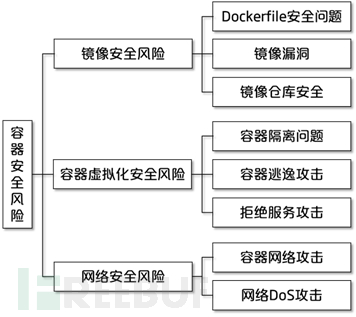
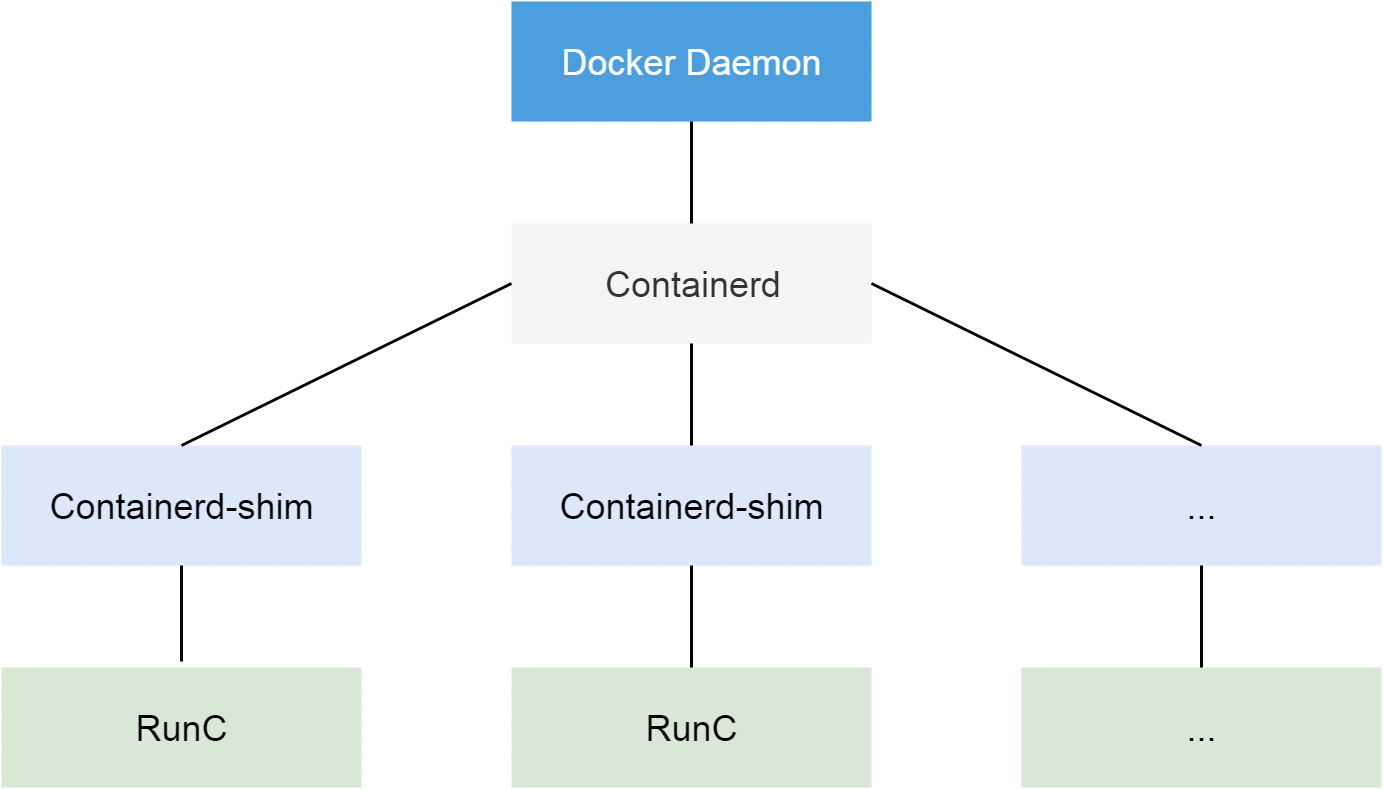
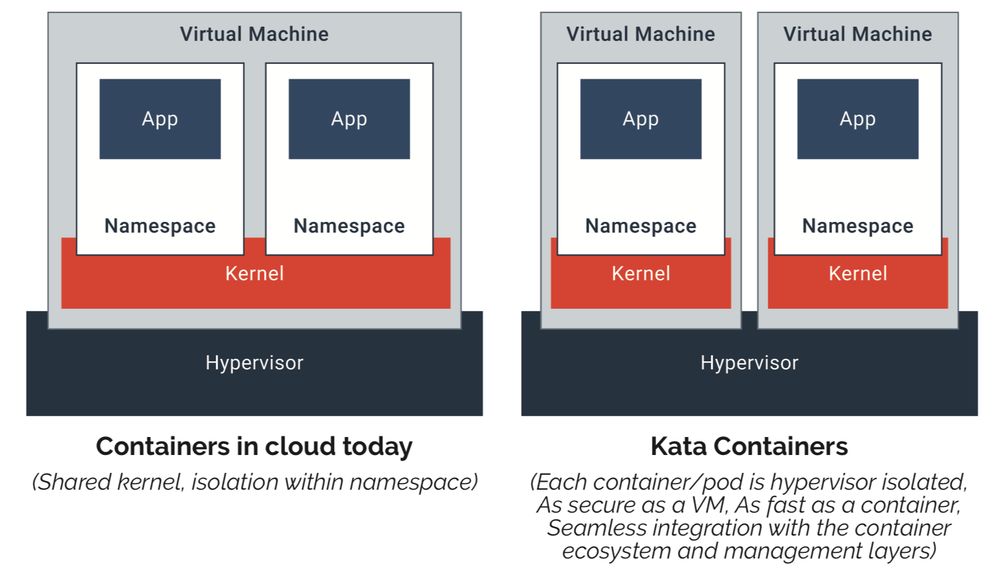
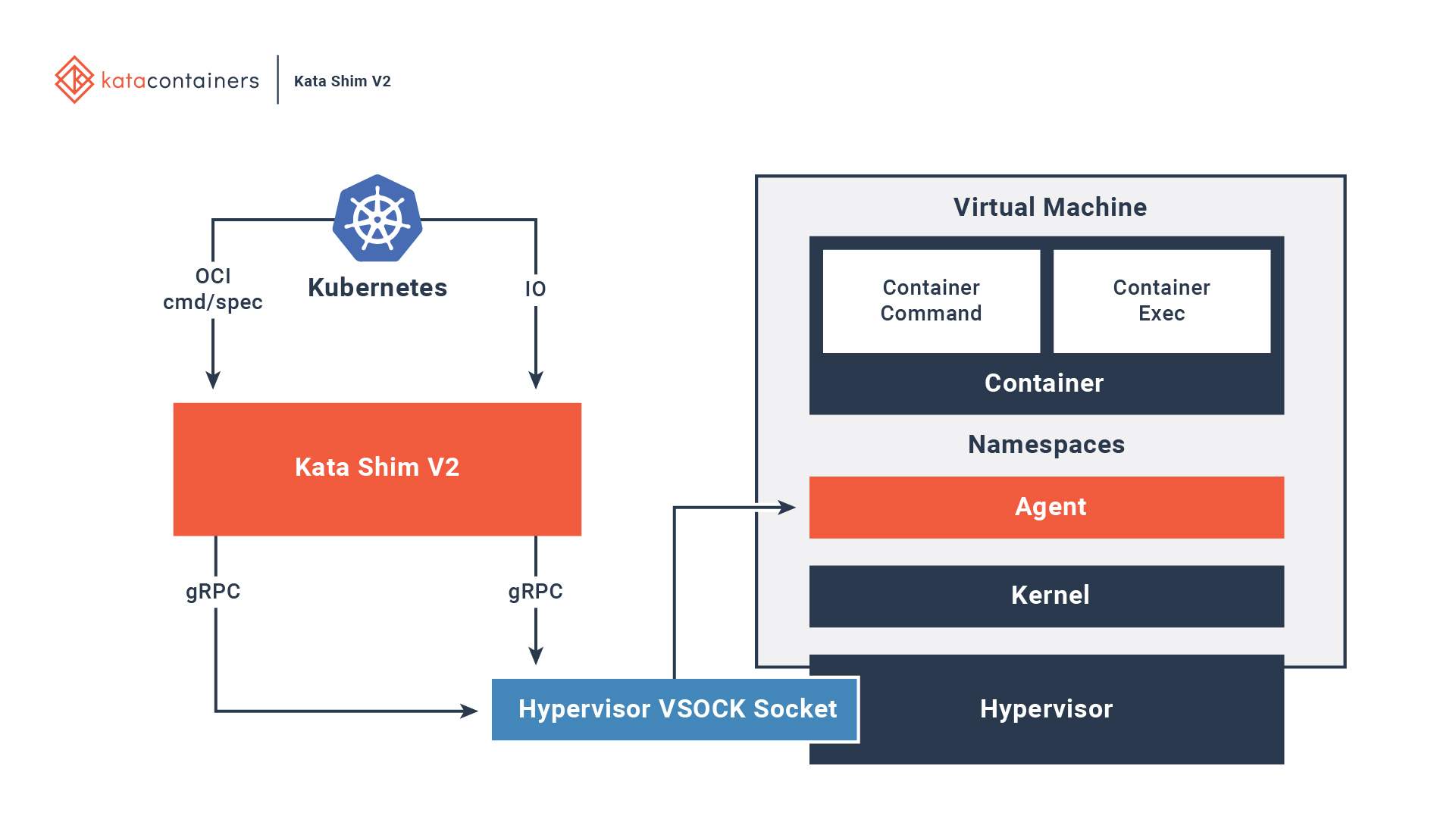
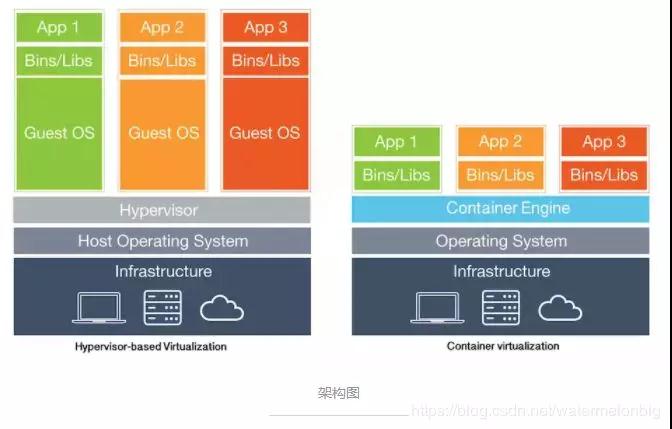
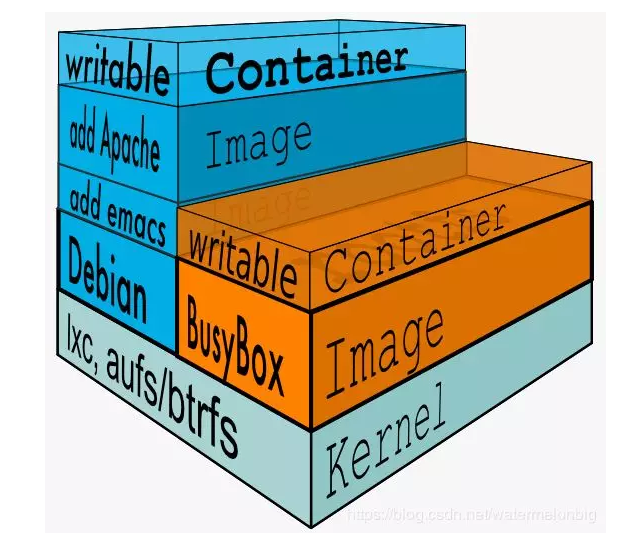
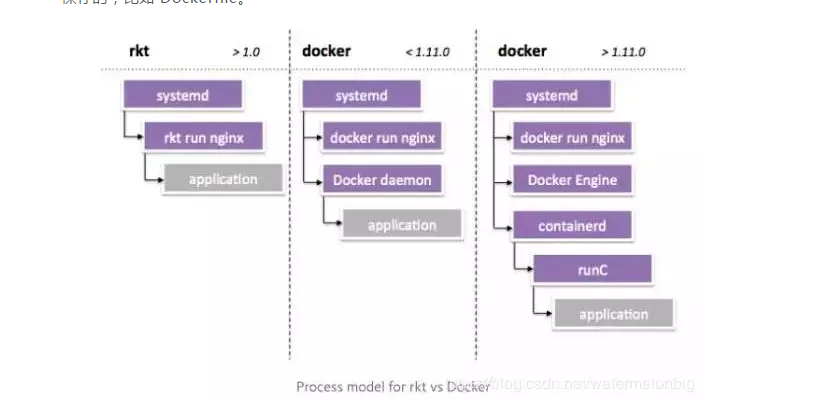
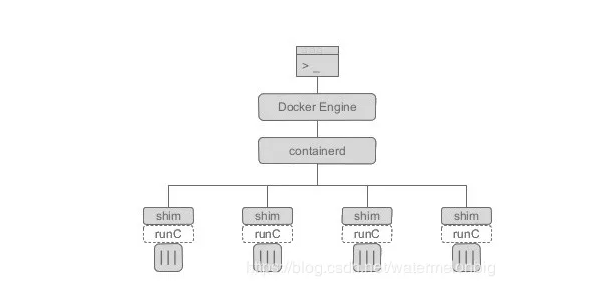
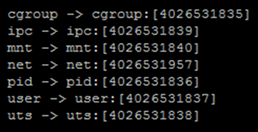
kata container基于轻量级虚拟机的容器,不同容器跑在一个个不同的虚拟机(kernel)上,比起传统容器提供了更好的隔离性和安全性,同时继承了容器快速启动和快速部署等优点。这也是本次想使用kata 的原因,能够提供比原生docker更好的隔离性,Kata 容器每个容器都使用专有内核,避免容器逃逸后影响宿主机的内核。
下面创建两个容器,一个使用 kata runtime,另一个使用默认的 runc。创建完容器之后,查看一下 kata container 的一些信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
admin@k8smaster:~$ docker run -d --name kata-test -p 8080:80 --runtime kata-runtime httpd:alpine ddbd72466c4ce862891538a8252a83450435b25f488cce98c9f8f9a8e51711e7 admin@k8smaster:~$ curl http://localhost:8080 <html><body><h1>It works!</h1></body></html> admin@k8smaster:~$ docker run -d --name runc-test -p 8082:80 httpd:alpine c7aff63e2d239ea0d27641398f0d3f108999ba3a125c6cef9f1330ccb75c93d4 admin@k8smaster:~$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c7aff63e2d23 httpd:alpine "httpd-foreground" 3 seconds ago Up 2 seconds 0.0.0.0:8082->80/tcp runc-test ddbd72466c4c httpd:alpine "httpd-foreground" About a minute ago Up About a minute 0.0.0.0:8080->80/tcp kata-test
root@k8smaster:/home/xdnsadmin# kata-runtime list # 需要root权限 ID PID STATUS BUNDLE CREATED OWNER a5468f62e87ea88889d8773247d8b7863f6c8de13fc0a2c6b65ed987fa04db77 23146 running /run/containers/storage/overlay-containers/a5468f62e87ea88889d8773247d8b7863f6c8de13fc0a2c6b65ed987fa04db77/userdata 2020-07-23T08:14:18.253804592Z #0
查看一下两个容器的内核版本
1 2 3 4 5 6 7 8 9 10 11 12
admin@k8smaster:~$ docker exec -it kata-test sh /usr/local/apache2 # uname -a Linux ddbd72466c4c 5.4.32-49.container #1 SMP Fri Jul 3 05:36:39 UTC 2020 x86_64 Linux /usr/local/apache2 # cat /proc/version Linux version 5.4.32-49.container (abuild@lamb04) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #1 SMP Fri Jul 3 05:36:39 UTC 2020
admin@k8smaster:~$ docker exec -it runc-test sh /usr/local/apache2 # uname -a # runc容器内核 Linux c7aff63e2d23 4.15.0-112-generic #113-Ubuntu SMP Thu Jul 9 23:41:39 UTC 2020 x86_64 Linux
admin@k8smaster:~$ uname -a #宿主机内核 Linux ubuntu 4.15.0-112-generic #113-Ubuntu SMP Thu Jul 9 23:41:39 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
OCI Open Container Initiative这是开放容器标准,也叫容器runtime,简单来说只要符合这个标准运行的就是容器,例如runC,Kata,gVisor这些runtime创建出来的都是OCI标准容器容器标准,也叫容器runtime,简单来说只要符合这个标准运行的,就是容器,例如runC,Kata,gVisor这些runtime创建出来的都是OCI标准容器
apiVersion:node.k8s.io/v1beta1# RuntimeClass is defined in the node.k8s.io API group kind:RuntimeClass metadata: name:kata handler:kata-runtime# handler 名称需要与/etc/crio/crio.conf配置一致
创建kata runtime class
1 2 3 4
admin@k8smaster:~$ kubectl apply -f k8s-runtimecleass.yaml admin@k8smaster:~$ kubectl get runtimeclass NAME HANDLER AGE kata kata-runtime 1m
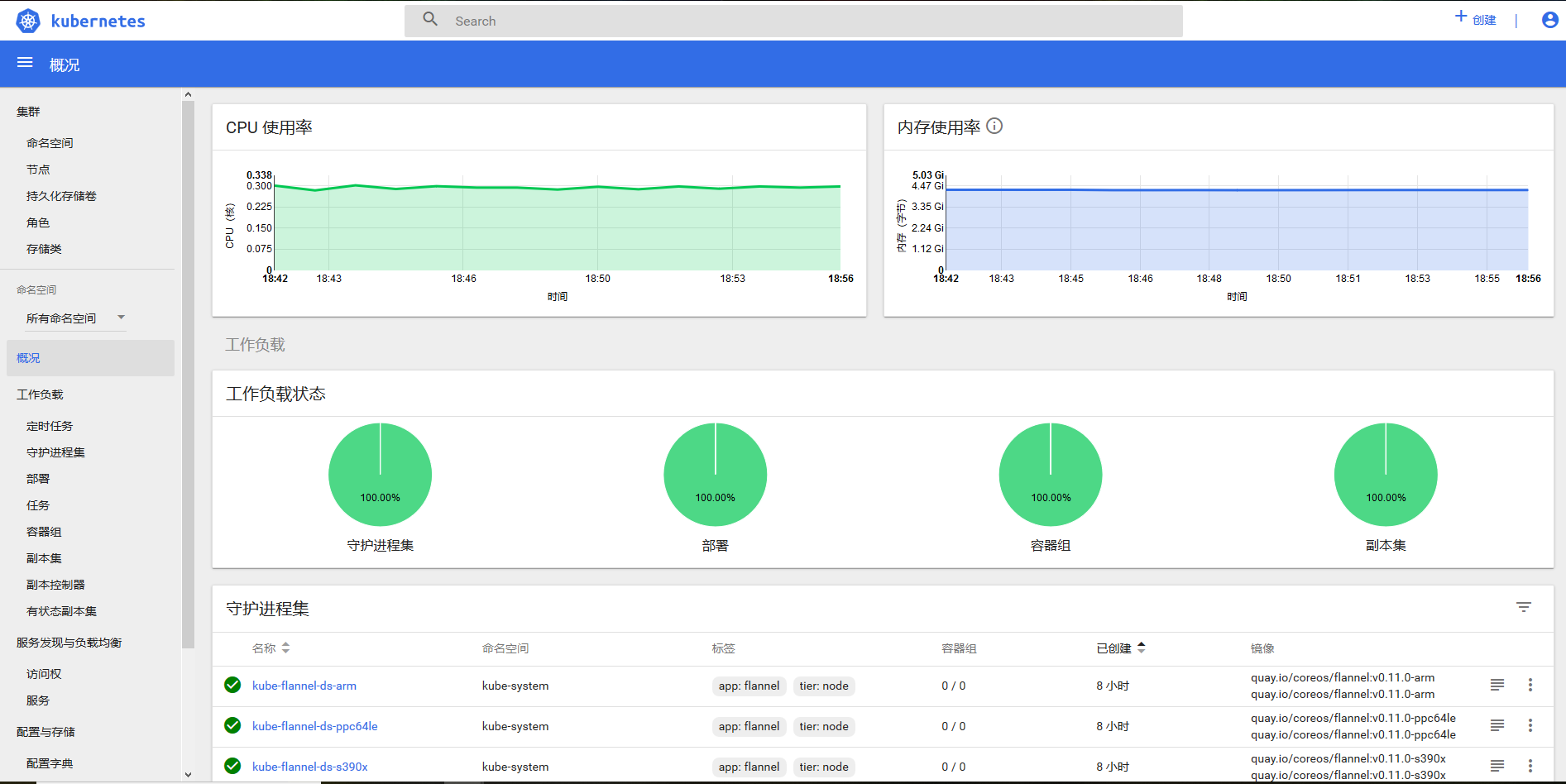
容器和微服务的结合创造了另外的热潮,也让服务发现成功了热门名词。可以轻松扩展微服务的同时,也要有工具来实现服务之间相互发现的需求。 DNS 服务器监视着创建新 Service 的 Kubernetes API,从而为每一个 Service 创建一组 DNS 记录。 如果整个集群的 DNS 一直被启用,那么所有的 Pod应该能够自动对 Service 进行名称解析。在技术实现上是通过kubernetes api监视Service资源的变化,并根据Service的信息生成DNS记录写入到etcd中。dns为集群中的Pod提供DNS查询服务,而DNS记录则从etcd中读取。
kube-dns:kube-dns是Kubernetes中的一个内置插件,目前作为一个独立的开源项目维护。Kubernetes DNS pod 中包括 3 个容器:kube-dns,sidecar,dnsmasq .
]]>
最近以来的一些NFV的思考
NFV已死-云杀死的https://louielong.github.io/nfv-is-dead.html2019-11-04T03:23:48.000Z2019-11-04T03:36:05.000Z本文翻译自Gartner: NFV Is Dead– the Cloud Killed It,可能存在翻译不准确的地方。
Enterprises are demanding a new generation of cloud-based wide-area networking services that’s swallowing up SD-WAN, killing network functions virtualization (NFV) and challenging existing telco business and technology models, according to Gartner analysts.
Gartner has given the new network delivery business model a name, and it’s an ugly one: SASE, pronounced “sassy,” which stands for the “Secure Access Service Edge.” And if Gartner is right, the effect on service providers’ business is going to be ugly too.
Gartner给新的网络交付业务模型起了一个名字,一个非常丑陋的名字:SASE,发音为“ sassy”,代表“安全访问服务边缘”(Secure Access Service Edge)。 如果Gartner是正确的,那么对服务提供商业务的影响也将是丑陋的。
The SASE transformation has been building for years. Five years ago, almost all enterprise applications and data lived in the data center, Gartner analyst Joe Skorupa tells Light Reading. Branch office networking connected to the data center, as did remote workers. Whatever cloud access was necessary then went to the data center first, then out to the public Internet.
“Now, applications are pretty much everywhere,” Skorupa says. Some are in the data center, some are outside of it. Mission-critical applications live in the cloud, including Workday, Microsoft Office 365, and custom applications written for Microsoft Azure and Amazon Web Services. “The data center is no longer the center of the universe,” he says.
“现在,到处都有应用程序,” Skorupa说。 有些在数据中心内,有些在数据中心外。 关键任务应用程序存在于云中,包括Workday,Microsoft Office 365和为Microsoft Azure和Amazon Web Services编写的自定义应用程序。 他说:“数据中心不再是宇宙的中心。”
Skorupa adds, “We have gone from having a ‘data center’ to having ‘centers of data,’ and they are all over the place.”
Skorupa补充说:“我们已经从拥有“数据中心”变为拥有“中心的数据”,并且它们遍布各处。”
Likewise, consumers of data aren’t just branch offices. Endpoints are mobile. “They’re a sales executive sitting in a car with a cup of coffee and an iPad,” Skorupa says. “They’re not funneling through the data center. It’s a hub and spoke. But the hub is the individual, which could be a person, could be an IoT device, and could be software.”
The new network architecture requires different technologies to suit different needs, Skorupa says. For example, a home worker doesn’t need SD-WAN because they’re not balancing multiple links, but that worker does need quality-of-service guarantees to make video calls. On the other hand, a branch office requires SD-WAN for security and path selection.
The changing nature of business requires changing security policies and technology as well, Skorupa says. “If it’s a contractor using an untrusted laptop logging in from Southeast Asia at two o’clock Sunday morning directly into Salesforce, trying to get at the entire client database, you want to apply a lot of security policy against that,” Skorupa says.
Additionally, enterprise locations need intrusion detection and prevention services (IDS/IPS), data loss prevention (DLP), anti-spam, anti-malware, whitelisting, blacklisting and so on. “The overhead of trying to keep that stuff patched is a nightmare. You’re always out of date. You’re not going to put seven boxes stacked up – and duct them to the back of my iPad when I’m traveling,” Skorupa says. Cloud delivery is the only model that makes sense.
He adds, “The only way to apply policy anywhere and everywhere, scaling up and scaling down as needed, delivering a set of functions you need on demand, is to deliver it primarily cloud-based.”
R.I.P. CPE That means on-premises equipment needs to go from being the standard way of delivering enterprise services to a specialized case, says the Gartner man.
Gartner负责人说,这意味着本地设备需要从提供企业服务的标准方式转变为特殊情况。
“The model says on-prem only when you must, cloud-delivered whenever you can,” Skorupa says.
Skorupa说:“该模型仅在必要时才在企业内部显示,并在可能的情况下通过云交付。”
This “represents an existential threat to NFV” because NFV depends on selling expensive boxes that happen to be x86-based. The cost benefits promised initially for NFV failed to materialize because vendors simply refused to lower their prices by a lot, Skorupa says.
NFV proved “incredibly complicated,” and while the telco industry struggled to make it work, “application consumption patterns changed and the branch was no longer the center of the universe, and a solution that was non-scalable and hard to maintain and expensive and complex winds up being obsoleted by something that is elastic and easy to maintain and it’s cloud delivered,” Skorupa says.
In a July note, Gartner recommends several steps for technology and service providers to succeed in the new market. They need to transform offerings to a cloud-native architecture, transform business models to “cloud-native-as-a service,” deliver “a clear vision” to the market, fill out their “portfolio organically, with the fewest acquisitions possible to minimize integration challenges and inconsistencies across services,” and invest in distributed real estate, such as PoPs and colocation facilities, to place service as close to the access point as required.
Gartner names several vendors as already network-security focused, including Cato Networks, Fortinet, Forcepoint, Juniper and Versa Networks. Other SD-WAN vendors without cloud-delivered security are partnering with Zscaler, Palo Alto Networks and others.
Of course, the industry being what it is, these vendors are going into paroxysms of joy by merely being mentioned by Gartner. Versa and Cato Networks put out press releases and statements on their websites, and zScaler devoted some discussion to the subject on an earnings call.
电信公司陷入困境 Cato Networks, for one, sees the shift to SASE as a competitive advantage. “Telcos are behind the eight-ball,” Yishah Yovel, Cato CMO and chief strategist, tells Light Reading. Telco networks are based on appliances, and they’re two years behind catching up on the cloud networking model.
Telcos are disadvantaged because they don’t own the code. “If I’m a Palo Alto or Zscaler, I have my own code. I already have some percentage of the SASE platform. Telcos don’t operate this way. They integrate other people’s code. That’s very dangerous for them, unless they become more of a software player.”
Looked at one way, Gartner’s SASE pitch is nothing new. Indeed, when a Cato Networks spokesman brought it to my attention a few weeks ago, I initially scoffed.
Normally I would have been more polite, but I was in a bad mood on account of being still jet-lagged and sleep deprived from a trip to Dallas, to Light Reading’s Network Virtualization & Software Defined Networking conference, which was all about the trends Gartner had apparently just discovered. And it wasn’t the first year we’ve done that conference; far from it. So my first reaction to the tip was, “Thank you, Captain Obvious!“
The software-defined networking (SDN) movement, launched at the beginning of the decade, was all about moving network intelligence into software for increased agility; the reason we don’t hear much about that anymore is because the philosophy has become mainstream.
More recently, AT&T, Orange and startup Rakuten are aggressively moving their networks to cloud architectures. Just last week, Colt launched a new line of universal CPE (uCPE) equipment, providing SD-WAN, firewall and other services to enterprises, based on NFV.
Still, NFV has attracted skeptics almost since its founding in 2012, and at about the same time Gartner issued its SASE note, we reported that critics were saying the technology is too rigid and monolithic for the cloud era, (though Prayson Pate, CTO, Edge Cloud, ADVA Optical Networking took issue with our report).
However, my initial dismissal was misplaced. Gartner does a good job of weaving together and articulating several long-term trends shaping the service provider business and networks. Gartner deserves credit for stepping back and summarizing a decade of trends in a few pages.
Also, Gartner is influential, particularly among enterprises who are service provider customers. Gartner’s SASE coinage means ideas about wide-area network virtualization and cloudification have gone mainstream. Telcos are going to start hearing demand for SASE, and need to be prepared to meet it.
python3 Python 3.5.2 (default, Nov 12 2018, 13:43:14) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import this The Zen of Python, by Tim Peters
Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
Beautiful is better than ugly. 优美胜于丑陋(Python 以编写优美的代码为目标) Explicit is better than implicit. 明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似) Simple is better than complex. 简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现) Complex is better than complicated. 复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁) Flat is better than nested. 扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套) Sparse is better than dense. 间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题) Readability counts. 可读性很重要(优美的代码是可读的) Special cases aren’t special enough to break the rules. Although practicality beats purity. 即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上) Errors should never pass silently. Unless explicitly silenced. 不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码) In the face of ambiguity, refuse the temptation to guess. 当存在多种可能,不要尝试去猜测 There should be one– and preferably only one –obvious way to do it. 而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法) Although that way may not be obvious at first unless you’re Dutch. 虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido ) Now is better than never. Although never is often better than right now. 做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量) If the implementation is hard to explain, it’s a bad idea. If the implementation is easy to explain, it may be a good idea. 如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准) Namespaces are one honking great idea – let’s do more of those! 命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)
也有简洁版的如下:
The Zen of Python, 蛇宗三字经 作者:Tim Peters 翻译:元创
Beautiful is better than ugly. 美胜丑 Explicit is better than implicit. 明胜暗 Simple is better than complex. 简胜复 Complex is better than complicated. 复胜杂 Flat is better than nested. 浅胜深 Sparse is better than dense. 疏胜密 Readability counts. 辞达意 Special cases aren’t special enough to break the rules. 不逾矩 Although practicality beats purity. 弃至清 Errors should never pass silently. 无阴差 Unless explicitly silenced. 有阳错 In the face of ambiguity, refuse the temptation to guess. 拒疑数 There should be one– and preferably only one –obvious way to do it. 求完一 Although that way may not be obvious at first unless you’re Dutch. 虽不至,向往之 Now is better than never. 敏于行 Although never is often better than right now. 戒莽撞 If the implementation is hard to explain, it’s a bad idea. 差难言 If the implementation is easy to explain, it may be a good idea. 好易说 Namespaces are one honking great idea – let’s do more of those! 每师出,多有名
# For identity v2, it uses OS_TENANT_NAME rather than OS_PROJECT_NAME. export OS_TENANT_NAME=admin
# Authentication username, belongs to the project above, recommend admin user. export OS_USERNAME=admin
# Authentication password. Use your own password export OS_PASSWORD=opnfv_secret
# Authentication URL, one of the endpoints of keystone service. If this is v3 version, # there need some extra variables as follows. export OS_AUTH_URL=http://xxxxxxxxxxxx:35357/v3
export OS_IDENTITY_API_VERSION=3
# Domain name or ID containing the user above. # Command to check the domain: openstack user show <OS_USERNAME> export OS_USER_DOMAIN_NAME=Default
# Domain name or ID containing the project above. # Command to check the domain: openstack project show <OS_PROJECT_NAME> export OS_PROJECT_DOMAIN_NAME=Default
# Special environment parameters for https. # If using https + cacert, the path of cacert file should be provided. # The cacert file should be put at $DOVETAIL_HOME/pre_config. export OS_CACERT=/path_to/pre_config/os_cacert export OS_INSECURE=false
# Set an existing role used to create project and user for vping test cases. # Otherwise, it will create a role 'Member' to do that. export NEW_USER_ROLE=xxx
compute: # The minimum number of compute nodes expected. # This should be no less than 2 and no larger than the compute nodes the SUT actually has. min_compute_nodes: 2
# Expected device name when a volume is attached to an instance. volume_device_name: vdb
nodes: - # This can not be changed and must be node0. name: node0 role: Jumpserver ip: xx.xx.xx.xx user: root password: root
- # This can not be changed and must be node1. name: node1 # This must be controller. role: Controller # This is the instance IP of a controller node, which is the haproxy primary node ip: xx.xx.xx.xx # User name of the user of this node. This user **must** have sudo privileges. user: root key_filename: /path_to/pre_config/id_rsa
process_info: - # The default attack process of yardstick.ha.rabbitmq is 'rabbitmq-server'. # Here can be reset to 'rabbitmq'. testcase_name: yardstick.ha.rabbitmq attack_process: rabbitmq
- # The default attack host for all HA test cases is 'node1'. # Here can be reset to any other node given in the section 'nodes'. testcase_name: yardstick.ha.glance_api attack_host: node2
Review the dovetail.log to see if all important information has been captured - in default mode without DEBUG.
Review the results.json to see all results data including criteria for PASS or FAIL.
Tempest and security test cases
Can see the log details in tempest_logs/functest.tempest.XXX.html and security_logs/functest.security.XXX.html respectively, which has the passed, skipped and failed test cases results.
This kind of files need to be opened with a web browser.
The skipped test cases are accompanied with the reason tag for the users to see why these test cases skipped.
The failed test cases have rich debug information for the users to see why these test cases failed.
Vping test cases
Its log is stored in vping_logs/functest.vping.XXX.log.
HA test cases
Its log is stored in ha_logs/yardstick.ha.XXX.log.
Stress test cases
Its log is stored in stress_logs/bottlenecks.stress.XXX.log.
Snaps test cases
Its log is stored in snaps_logs/functest.snaps.smoke.log.
VNF test cases
Its log is stored in vnf_logs/functest.vnf.XXX.log.
3.5 测试失败排查
1)无法获取节点信息
节点信息获取失败并不影响测试执行,可以在dovetail容器中执行以下命令查找失败原因
1
ansible all -m setup -i XX/results/inventory.ini --tree XX/results/sut_hardware_info
2)dpdk错误相关
我的测试环境是os-nosdn-ovs-ha使用了DPDK网卡,有时由于变量传递的原因导致测试过程中,虚机的flavor没有设置'hw:mem_page_size':'large',因此导致虚拟创建后无法连接而报错,可以在测试过程中查看openstack flavor list --debug查看是否是此问题,如果是此类问题只能报告官方修复了。
3) 其他测试用例失败
通过dovetail的不清除选项保留测试过程中启动的容器,然后一步一步排查
1
$ dovetail run --offline --debug --testcase xxx -n
ERROR nova.compute.manager [req-94c955d9-9c94-4536-90e2-d21928344444 381fdf4b65aa45ef98a2ad20bc4bd079 4353036cc27542cf84e1bccf1b4bfe33 - default default] [ instance: 655eccd6-cafb-4291-b55a-c53dd000a8e4] Build of instance 655eccd6-cafb-4291-b55a-c53dd000a8e4 aborted: Volume 0e4150db-567f-4ae0-a947-8fc7a0d624f0 did not finish being created even after we waited 207 seconds or 61 attempts. And its status is downloading.: BuildAbortException: Build of instance 655eccd6-cafb-4291-b55a-c53dd000a8e4 aborted: Volume 0e4150db-567 f-4ae0-a947-8fc7a0d624f0 did not finish being created even after we waited 207 seconds or 61 attempts. And its status is downloading.
Number of times to retry block device allocation on failures. Starting with Liberty, Cinder can use image volume cache. This may help with block device allocation performance. Look at the cinder image_volume_cache_enabled configuration option.
按照官方文档在安装完Magnum后通过openstack coe service list来查看是否安装成功,如果该命令执行失败通过查看/var/log/magnum/magnum-api.log来排查问题。但是,该命令执行成功也不代表这Magnum的服务能够正常使用,后续使用中主要查看的是Magnum调度的日志/var/log/magnum/magnum-conductor.log。
2.1 magnum-api 报错
Magnum API报错 ,如下所示,根据[4],新的稳定版代码已修复但是安装的deb包并不是最新的代码
File “/usr/lib/python2.7/dist-packages/magnum/common/keystone.py”, line 47, in auth_url return CONF[ksconf.CFG_LEGACY_GROUP].auth_uri.replace(‘v2.0’, ‘v3’)
AttributeError: ‘NoneType’ object has no attribute ‘replace’
ERROR heat.engine.resource raise exception.ResourceFailure(message, self, action=self.action) ERROR heat.engine.resource ResourceFailure: resources[0]: Property error: resources.docker_volume.properties.volume_type: Error validating value ‘’: The VolumeType () could not be found.
1)Check if you have any volume types defined.
1
openstack volume type list
2)If there are none, create one:
1
openstack volume type create volType1 --description "Fix for Magnum" --public
3)Then in /etc/magnum/magnum.conf add this line in the [cinder] section:
2019-04-10 15:40:50.675 20235 ERROR magnum.conductor.handlers.common.cert_manager [req-c31e7588-a486-4ea8-8adc-16ff8f37b284 - - - - -] Failed to generate certificates for Cluster: e579 0f96-e8c5-49c5-82f9-87faf8438585: CertificateStorageException: Could not store certificate: [Errno 2] No such file or directory: ‘/var/lib/magnum/certificates/5e8beb02-9378-4e8c-8b4d-1 cae933de665.crt’
同时,在修复此问题的过程中查看到一个警告,该警告对于使用过程也造成了很大的影响Auth plugin and its options for service user must be provided in [keystone_auth] section. Using values from [keystone_authtoken] section is deprecated.: MissingRequiredOptions: Auth plugin requires parameters which were not given: auth_url
ERROR oslo_messaging.rpc.server [req-4a8e8e2d-cae0-4113-a49d-57bb91c03b8d - - - - -] Exception during message handling: EndpointNotFound: http://ctl01:9511/v1 endpoint for identity service not found …. ERROR oslo_messaging.rpc.server File “/usr/lib/python2.7/dist-packages/magnum/conductor/handlers/cluster_conductor.py”, line 68, in cluster_create ERROR oslo_messaging.rpc.server cluster_driver.create_cluster(context, cluster, create_timeout) …. ERROR oslo_messaging.rpc.server File “/usr/lib/python2.7/dist-packages/keystoneauth1/access/service_catalog.py”, line 464, in endpoint_data_for ERROR oslo_messaging.rpc.server raise exceptions.EndpointNotFound(msg) ERROR oslo_messaging.rpc.server EndpointNotFound: http://ctl01:9511/v1 endpoint for identity service not found
使用命令openstack endpoint list | grep public查看相关的endpoint。
/var/lib/cloud/instance/scripts/part-006: line 13: /etc/etcd/etcd.conf: No such file or directory /var/lib/cloud/instance/scripts/part-006: line 26: /etc/etcd/etcd.conf: No such file or directory /var/lib/cloud/instance/scripts/part-006: line 38: /etc/etcd/etcd.conf: No such file or directory
You should now deploy a Pod network to the cluster. Run "kubectl apply -f [Podnetwork].yaml" with one of the addon options listed at: http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node as root:
}, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": {
}, "code": 403 }
重置初始化
1
xdnsadmin@k8smaster:~$ kubeadm reset
忘记了token,可以通过命令查看
1 2 3
xdnsadmin@k8smaster:~$ kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS zsrpzu.lh831z4t4ht3vm1k 15h 2019-03-01T09:40:53+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
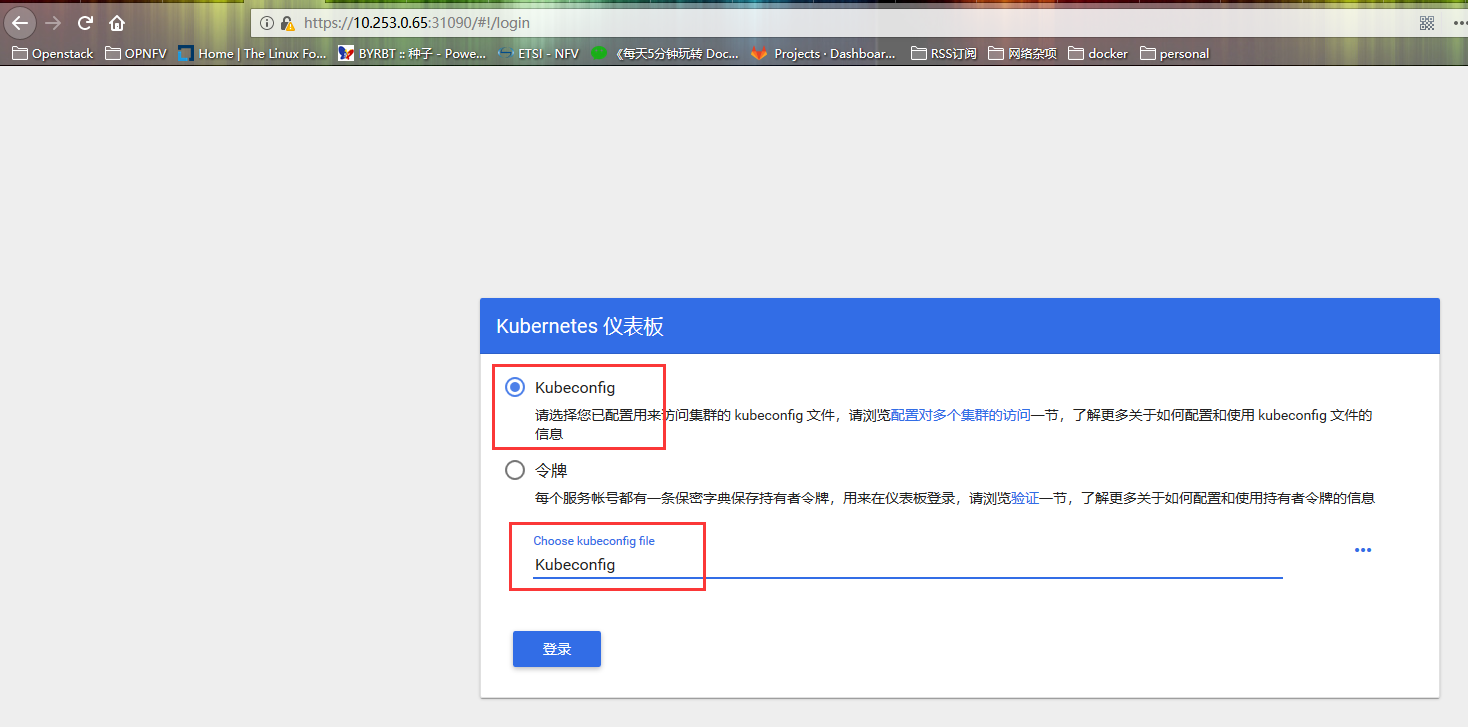
xdnsadmin@k8smaster:~/workplace/k8s/dashboard$ kubectl -n kube-system get service kubernetes-dashboard NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes-dashboard NodePort 10.97.229.208 <none> 443:31090/TCP 7h47m
# Set OS version for target hosts # Ubuntu16.04 or CentOS7 export OS_VERSION=xenial #指定待部署节点的系统版本 # Set ISO image corresponding to your code export TAR_URL=file:///home/opnfv/download/opnfv-6.2-m.tar.gz #指定下载的系统安装文件
# Set hardware deploy jumpserver PXE NIC # You need to comment out it when virtual deploy. export INSTALL_NIC=eth0 #指定PXE网卡 # DHA is your dha.yml's path export DHA=/home/opnfv/compass4nfv/deploy/conf/hardware_environment/bii-pod1/os-nosdn-nofeature-ha.yml #指定部署策略模板
# NETWORK is your network.yml's path export NETWORK=/home/opnfv/compass4nfv/deploy/conf/hardware_environment/bii-pod1/network.yml #指定待部署节点的网络配置
[root@compass-tasks /]# ssh root@10.20.0.53 Warning: Permanently added '10.20.0.53' (ECDSA) to the list of known hosts. Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-87-generic x86_64)
* Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Last login: Fri Nov 23 17:23:21 2018
root@ubuntu:~# ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null root@10.20.0.51 ... root@10.20.0.51's password: ... You have new mail. Last login: Tue Dec 11 10:02:26 2018 from 10.20.0.1 root@ctl02:~# lxc-attach --name ctl02_ceph-mon_container-2a24ec76 root@ctl02-ceph-mon-container-2a24ec76:~# cat /etc/apt/sources.list.d/download_ceph_com_debian_luminous.list #deb http://download.ceph.com/debian-luminous xenial main deb http://mirrors.ustc.edu.cn/ceph/debian-luminous/ xenial main
Traceback (most recent call last): File “/home/opnfv/compass4nfv/deploy/client.py”, line 1136, in main() File “/home/opnfv/compass4nfv/deploy/client.py”, line 1131, in main deploy() File “/home/opnfv/compass4nfv/deploy/client.py”, line 1086, in deploy client.get_installing_progress(cluster_id, ansible_print) File “/home/opnfv/compass4nfv/deploy/client.py”, line 1029, in get_installing_progress _get_installing_progress() File “/home/opnfv/compass4nfv/deploy/client.py”, line 1026, in _get_installing_progress raise RuntimeError(“installation timeout”) RuntimeError: installation timeout
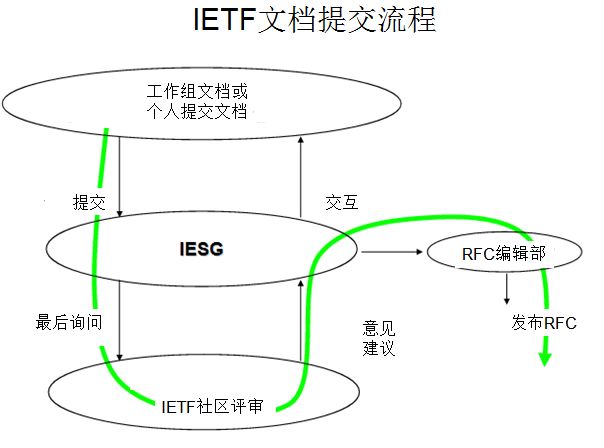
在通信和计算机行业一谈到标准提到最多的就是RFC,没接触RFC之前一直不明白RFC到底是什么。RFC的英文是“Request for Comments”,即“请求建议”,当某家机构或团体开发出了一套标准或提出对某种标准的设想,想要征询外界的意见时,就会在Internet上发放一份RFC,对这一问题感兴趣的人可以阅读该RFC并提出自己的意见;绝大部分网络标准的指定都是以RFC的形式开始,经过大量的论证和修改过程,由主要的标准化组织所指定的,但在RFC中所收录的文件并不都是正在使用或为大家所公认的,也有很大一部分只在某个局部领域被使用或并没有被采用,一份RFC具体处于什么状态都在文件中作了明确的标识。
第一步RFC的出版是作为一个Internet草案发布,可以阅读并对其进行注释。准备一个RFC草案,我们要求作者先阅读IETF的一个文档”Considerations for Internet Drafts”. 它包括了许多关于RFC以及Internet草案格式的有用信息。作者还应阅读另外一个相关的文档RFC 2223 “Instructions to Authors”一旦文档有了一个ID号后,你就可以向rfc-editor@rfc-editor.org发送e-mail,说你觉得这个文档还可以,能够作为一个有价值或有经验的RFC文档。RFC编辑将会向IESG请求查阅该文档并给其加上评论和注释。你可以通过RFC队列来了解你的文档的进度。一旦你的文档获得通过,RFC编辑就会将其编辑并出版。如果该文档不能出版,则会有email通知作者是什么原因。作者有48个小时来校对RFC编辑的意见。我们强烈建议作者要检测拼写错误和丢字的错误,应该确保有引用,联系和更新相关的信息。如你的文档是一个MIB,我们则要你对你的代码作最后一次检测。一旦RFC文档出版,我们就不会对其进行更改,因此你应该对你的文档仔细的检查。有时个别的文档会被正从事同一个项目的IETF工作组收回,如是这种情况,则该作者会被要求和IETF进行该文档的开发。在IETF中, Area Directors (ADs) 负责相关的几个工作组。这些工作者所开发的文档将由ADs进行校阅,然后才作为RFC的出版物。如要获得关于如何写RFC文档和关于RFC的Internet标准制定过程的更多详细信息,请各位参见:RFC 2223 “Instructions to RFC Authors”。
Internet standards (sometimes called “full standards”)
互联网标准(有时称为“完全标准”)
Best current practices (BCP) documents
当前最佳实践 (BCP) 文档
Informational documents
信息性文档
Experimental documents
实验性文档
Historic documents
历史性文档
[NOTE]Only the first two, proposed and full, are standards within the IETF. A good summary of this can be found in the aptly titled [RFC 1796], “Not All RFCs Are Standards”.
<?xml version="1.0" encoding="US-ASCII"?> <!-- This is built from a template for a generic Internet Draft. Suggestions for improvement welcome - write to Brian Carpenter, brian.e.carpenter @ gmail.com This can be converted using the Web service at http://xml.resource.org/ --> <!DOCTYPE rfc SYSTEM "rfc2629.dtd"> <!-- You want a table of contents --> <!-- Use symbolic labels for references --> <!-- This sorts the references --> <!-- Change to "yes" if someone has disclosed IPR for the draft --> <!-- This defines the specific filename and version number of your draft (and inserts the appropriate IETF boilerplate --> <?rfc sortrefs="yes"?> <?rfc toc="yes"?> <?rfc symrefs="yes"?> <?rfc compact="yes"?> <?rfc subcompact="no"?> <?rfc topblock="yes"?> <?rfc comments="no"?> <rfccategory="info" docName="draft-long-nfv-nfv-decoupling-test-00" ipr="trust200902">
<t><liststyle="symbols"> <t>Virtualized Network Function (VNF).</t> <t>Element Management (EM).</t> <t>NFV Infrastructure, including: Hardware and virtualized resources, and Virtualization Layer.</t> <t>Virtualized Infrastructure Manager(s) (VIM).</t> <t>NFV Orchestrator.</t> <t>VNF Manager(s).</t> <t>Service, VNF and Infrastructure Description. Operations and Business Support Systems (OSS/BSS).</t> </list></t>
效果图
对于列表的格式使用style标签,可选参数有
“empty”
For unlabeled list items; it can also be used for indentation purposes (this is the default value when there is an enclosing list where the style is specified).
“hanging”
For lists where the items are labeled with a piece of text.
The label text is specified in the “hangText” attribute of the <t> element (Section 2.38.2).
“letters”
For ordered lists using letters as labels (lowercase letters followed by a period; after “z”, it rolls over to a two-letter format). For nested lists, processors usually flip between uppercase and lowercase.
“numbers”
For ordered lists using numbers as labels.
“symbols”
For unordered (bulleted) lists.
The style of the bullets is chosen automatically by the processor (some implementations allow overriding the default using a Processing Instruction).
footer: # Specify the date when the site was setup. # If not defined, current year will be used. since:2015
# Icon between year and copyright info. icon: # Icon name in fontawesome, see: https://fontawesome.com/v4.7.0/icons # `heart` is recommended with animation in red (#ff0000). name:user # If you want to animate the icon, set it to true. animated:true # Change the color of icon, using Hex Code. color:"#808080"
# If not defined, will be used `author` from Hexo main config. copyright: # -------------------------------------------------------------
# Hexo link (Powered by Hexo).
powered:true
theme: # Theme & scheme info link (Theme - NexT.scheme). enable:true # Version info of NexT after scheme info (vX.X.X). version:true
将Application ID、Search-only API key以及indexName都替换成自己的信息。同时需要将next主题中algolia搜索开关打开
algolia_search:
enable: true
执行下述命令
1 2 3 4
$export HEXO_ALGOLIA_INDEXING_KEY=Search-Only API key # Use Git Bash #set HEXO_ALGOLIA_INDEXING_KEY=Search-Only API key # Use Windows command line $ hexo clean $ hexo algolia
root@HA-1:~# mysql -uroot -p mysql> GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO sync@'192.168.10.102' IDENTIFIED BY 'sync'; mysql> flush privileges;
随后查看数据库状态信息
1 2 3 4 5 6 7
mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 465 | test,test1 | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
root@HA-2:~# mysql -uroot -p mysql> GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO sync@'192.168.10.101' IDENTIFIED BY 'sync'; mysql> flush privileges;
随后查看数据库状态信息
1 2 3 4 5 6 7
mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000002 | 465 | test,test1 | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
case$STATEin "MASTER") if [ "${get_pid}" == "" ]; then log"$service_name service isn't exist." log"Try to restart $service_name service." $service_cmd start if [ $? -eq 0 ]; then log"restart $service_name service successfully." else log"restart $service_name service failed." exit 1 fi fi exit 0 ;; "BACKUP") if [ "${get_pid}" == "" ]; then log"$service_name service isn't exist." log"Try to restart $service_name service." $service_cmd start if [ $? -eq 0 ]; then log"restart $service_name service successfully." else log"restart $service_name service failed." exit 1 fi fi exit 0 ;; "FAULT") exit 0 ;; *) exit 1 ;; esac
root@HA-2:~# mysql -h192.168.10.103 -uroot -p mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2119 Server version: 5.7.21-0ubuntu0.16.04.1-log (Ubuntu)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show variables like 'server_id'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 2 | +---------------+-------+ 1 row in set (0.00 sec)
因为预设的 NTP Server 本身的时间计算是依据 BIOS 的芯片震荡周期频率来计算的,但是这个数值与上层 Time Server 不见得会一致啊!所以 NTP 这个 daemon (ntpd) 会自动的去计算我们自己主机的频率与上层 Time server 的频率,并且将两个频率的误差记录下来,记录下来的档案就是在 driftfile 后面接的完整档名当中了!关于档名你必须要知道:
statistics loopstats peerstats clockstats filegen loopstats file loopstats type day enable filegen peerstats file peerstats type day enable filegen clockstats file clockstats type day enable
# 上层ntp server. pool ntp1.aliyun.com iburst pool ntp2.aliyun.com iburst pool ntp3.aliyun.com iburst pool ntp4.aliyun.com iburst # 清华源提供IPv4和IPv6双栈 pool ntp.tuna.tsinghua.edu.cn iburst perfer
# Use Ubuntu's ntp server as a fallback. pool ntp.ubuntu.com
# Needed for adding pool entries restrict source notrap nomodify noquery
# If you want to provide time to your local subnet, change the next line. # (Again, the address is an example only.) #broadcast 192.168.123.255
# If you want to listen to time broadcasts on your local subnet, de-comment the # next lines. Please do this only if you trust everybody on the network! #disable auth #broadcastclient
#Changes recquired to use pps synchonisation as explained in documentation: #http://www.ntp.org/ntpfaq/NTP-s-config-adv.htm#AEN3918
#server 127.127.8.1 mode 135 prefer # Meinberg GPS167 with PPS #fudge 127.127.8.1 time1 0.0042 # relative to PPS for my hardware